The Silicon Stack
Posted September 9, 2022 ‐ 13 min read
A peek into the tools we use to build and deploy software.
In the Beginning…
God said, "Let there be light," and there was LAMP. And it was good.
…or maybe it wasn't, because then there was MEAN and LYME and an infinite alphabet soup of derivatives.
Okay, maybe that’s a bit heretical, but then again, software development is rife with heated rivalries that can have an almost religious zeal to them: tabs vs spaces, Vim vs Emacs, Windows vs Linux, etc – epic battles between light and dark (mode).
In our particular quest for a software stack, we’re going to (attempt to) avoid petty tribalism and look at the tools available to us with clear eyes.
Choosing a Stack
As a software organization (and 501c3!) thinking about scale and efficiency, it makes sense for us to standardize on a set of technologies that we’ll use for building things, so that we can develop expertise and an ecosystem of tooling that’ll pay dividends in the long run.

But which technologies? What tooling? We’re going to be stuck with the consequences of these decisions for years to come, so ideally we’d like to make good choices here.
As with most things, we try to let our decisions be guided by the goals we want to achieve. In rough order of priority, those goals look something like:
Goal #1: Build secure systems
The tools we invest in should make it easy to build secure software. That means auditable and understandable software supply chains, proven technologies used in production by organizations storing sensitive info, data encryption at rest and in transit, etc. The things we build are effectively useless if they can’t be trusted to protect sensitive data.
Goal #2: Keep developer velocity high
In the short term (and likely even in the long term), our biggest expense will be engineering time. Given that, we want to invest in tools that maximize what we can do with a given unit of time, to get the best bang for our proverbial software engineering buck. This means using tools that are well-tested and well-documented so we aren’t spending hours debugging basic functionality. It also means not reinventing the wheel when there’s a high-quality (and appropriately licensed) component that will do the job well.
Goal #3: Manage costs effectively
The software lifecycle doesn’t end when the codebase is feature-complete. In a lot of ways, that’s really just the beginning. With any luck, that service will be running for a long time, and that means managing the ongoing costs of deployment, both in terms of maintenance (bug fixes, additional features, logging, monitoring, etc) and consumed resources (compute, networking, storage, etc).
Every dollar that we don’t spend can go towards subsidizing future projects, and every dollar our clients don’t have to spend can go towards their mission. To maximally support both ends of that equation, we want to design systems that can be run cheaply, and with little human oversight.
The Goals: A Recap
So, to sum it up, we want to use technologies that are secure, proven, well-tested, well-supported, well-documented, easy to use, actively maintained, generally attuned to the needs of web applications, and performant. We ideally want something we’re already somewhat familiar with, or can be learned easily. Oh, and it needs to play nicely with major cloud platforms.

Anatomy of a Stack
Where a ‘software stack’ begins and ends is up for debate, and for the purposes of this discussion, we’re going to take a very liberal and all-encompassing view, reaching from development through production.
The rest of this post will detail the various decisions we’ve made, and why we’ve made them.
Cloud Provider: GCP 1
We’re using Google’s Cloud Platform (GCP) as our go-to cloud provider. In this day and age, all the major cloud providers offer the same basic set of managed + unmanaged services at largely similar costs, so it came down to a few details relevant to our organization and needs. I’ll skip the full analysis, but the main criteria for us were:
- Sustainability - We’re (at least in part) an environmental nonprofit, and we feel it’s important that our actions reflect our ideals. Accordingly, we looked at what the major cloud providers were doing around managing their carbon footprints. Both our own digging and the external analyses we looked at skewed heavily towards GCP, with Azure a close second, and AWS a distant third. GCP provides tooling for identifying data center regions with the lowest CO2 emissions, and we run our infrastructure (and client infrastructure) in those regions.
- Free-tier pricing + sub-accounts - Since we’re optimizing for low operating cost for our clients, we’ll want to actively leverage the free tiers available to us on a per-product basis. In particular, both Cloud Run (compute) and Cloud Storage (object storage) have generous enough free tiers to cover the entire cost of modestly provisioned services. Because free tier limits are calculated per billing account, we can structure our projects/folders/billing such that each client gets their own free tier quota.
Compute Platform: Cloud Run
Once you’ve chosen a cloud provider, you need to choose which of their dozens of compute products to run your software on. These days, this mostly boils down to “how and where do I want to run my Docker containers?”

For us, the choice was pretty simple: Cloud Run.
Cloud Run is like App Engine or Heroku, but specifically for Docker containers.2. It’s basically Kubernetes with a layer or two of additional abstraction, and it has all the things we’re looking for, namely scale-to-zero semantics, per-request pricing, and free tier quota.
And it doesn’t have some of the drawbacks of running on a more managed serverless platform like Cloud Functions.3 We can happily use it for request/response-oriented traffic4 and async task processing5, but it’s not as low-level as something like raw Compute Engine VMs, which would then require us to run our own load balancers (a minimum of ~$20/month per environment) and more actively manage scaling via instance groups.
For us, Cloud Run is the Goldilocks of compute platforms: not too low-level, not too high-level, just right.
Application Stack: GraphQL, Nuxt, Postgres, oh my!
Arguably the most important parts of ’the stack’ are the technologies we use to actually build things. These things overwhelmingly dictate important details, like developer experience + velocity, performance, stability, and how end-users experience our applications. No pressure.
GraphQL
One of the more contentious decisions for us was to standardize on GraphQL for our user-facing API layer.6 We had comparatively little experience with it, and it’s a fairly different paradigm than the endpoint-per-thing gRPC/REST-style APIs we usually go for.
Our main motivation was the Adventure Scientists project, where end-users would frequently be accessing the app in poor network conditions. GraphQL allows us to bundle data requests into a single network request, minimizing round trips and overall latency.
Of course, this comes with tradeoffs. Implementing resolvers with nested entities on the backend introduces additional complexity, as does the necessary DoS mitigations to prevent malicious queries from overloading a service. Productionizing a GraphQL service looks different than an HTTP/REST service.7 The ability to selectively load only the data that was requested is a useful performance optimization, but can also clutter up the application logic.
At this point, we’ve built a pretty large backend service around GraphQL and are overall happy with the results. We’ll likely continue to build tooling around GraphQL and use it for future projects.
Nuxt
We use Nuxt (v3) on the frontend, taking advantage of universal rendering so that initial requests to the server come back to the client fully populated with data from our backend. All subsequent navigation happens entirely client-side, with requests issued only for lazy-loaded components and to the API for data + mutations.
In short, we get the best of all worlds: the initial snappiness and SEO of server-rendered applications, the single-language ease of development and cacheability of client-rendered applications, and the type-checked goodness8 of a statically typed language.
The price that we pay for this is a bit of additional complexity: since most
code can be run on the server (for initial page load) or the client (for any
subsequent page), we can’t assume we have access to window or localStorage
or any other browser APIs. In turn, we need to be more careful when using
third-party libraries, like rich text editors and map views, which frequently
do make those assumptions.
We deploy Nuxt to Firebase Hosting for static asset serving, and Cloud Functions for the server-side rendering component. This is conveniently supported directly by Nuxt and requires virtually no effort on our part.
PostgreSQL
Our requirements around the data persistence layer are pretty uninteresting. We’d like to store structured data, and be able to query it back. It can’t be noticeably slow. It’s unlikely we’ll ever need to build for use cases that can’t be served by vertically scaling a managed SQL instance, and we’d prefer to avoid the vendor lock-in of a NoSQL or a proprietary SQL.9 Pretty much any reasonable database would do.
We chose Postgres because we like elephants
more than dolphins of the community, robust support for JSON and full text
search, permissive license, and because it seems like every week there’s
a
new
platform being built on top of it, which bodes well
for its future longevity and momentum. Also, it’s
available on Cloud SQL, which
is great because we have no desire to self-host our database layer.
TypeScript in the front…
On the frontend we use TypeScript, because we’re firm believers that humans shouldn’t bother doing manual toil if we can convince a computer to do it for us. TypeScript has mercifully helped us avoid hundreds of potentially painful debugging sessions that plain JavaScript would have welcomed us into with open arms.
Nuxt also supports Typescript out of the box, which is awfully convenient.
…Golang in the back
On the backend we use Go. Go is a great language for a bunch of reasons, here are some that are particularly relevant to us:
- Simple, typed language - Much like TypeScript above, using a typed language on the backend lets the compiler do a lot of work for us, which gets especially important as a codebase gets larger. Beyond that, Go is just simple, I’ve found that people who are familiar with Java/Python/C/C++/etc can usually pick up Go and be writing fairly idiomatic code in a week. It doesn’t have a lot of features, which makes it hard to do things particularly wrong.
- Extensive library support - There’s frequently one or two high-quality libraries for doing a given task (e.g. a Postgres client, K/V store, JWT parsing, etc), and Go is well-supported by popular software libraries and systems (Protobuf/gRPC, GraphQL, K8s, Bazel, etc). Beyond that, something like 70% of Cloud Native Computing Foundation projects are written in Go, meaning Go has extensive support in cloud-y use cases.
- Quick compilation, self-contained binaries - Fast compilation
makes for a good developer experience, and small, self-contained binaries make
for easy deployment (e.g. on Cloud Run in Docker, on bare metal, for throwing a
quick CLI in your
$PATH, etc). - Performant and concurrent - While performance isn’t our highest priority, as most applications we build will be small scale compared to much of what exists today, Go’s performance will frequently mean we can can serve thousands of requests a second from a single Raspberry Pi-sized instance, staying within the free tier for our compute services. Similarly, built- in support for concurrency is useful in a server environment for efficient resource use (e.g. suspending routines that are making network connections to DBs or other services).
Build Systems: Bazel
While we could totally get by without using a dedicated build system, there are a bunch of reasons it makes sense for us to adopt and standardize on one:
- Reproducible builds - We take the security of client applications pretty seriously, and being able to build bit-identical binaries for a given Git commit of a repo is a big part of having an auditable software supply chain.
- Caching - Go compiles quickly, so caching build artifacts isn’t as big a deal, but caching still speeds up other parts of the build process (e.g. code generation tools), and means that our CI environment can test only what has changed, saving us money.
- Standardized interface - Instead of running
cargo buildorgo test ./…orpython -m test …, everything is justbazel build //…to build all the code andbazel test //…to test all the code. This is great for CI, and for quick sanity checks that large-scale changes haven’t broken anything too terribly. - Code generation - We use Bazel to manage code generation for things like Protocol Buffers and GraphQL, which means they get automatically updated and don’t need to be manually updated and checked into source control.
In particular, Bazel has the benefit of being a mature build system with great
support for Go,
Docker,
Protocol Buffers, and more,
which means we can bazel build our way to a Docker container that is ready to
run on Cloud Run, or any containerized cloud environment. It also helps that we
have extensive experience using Blaze, Google’s internal version of Bazel.
While Bazel does have support for JavaScript, we haven’t bit the bullet and migrated our frontend infrastructure to it, as it seems to be more effort to setup and maintain than it’s worth.
Unrolling the Stack
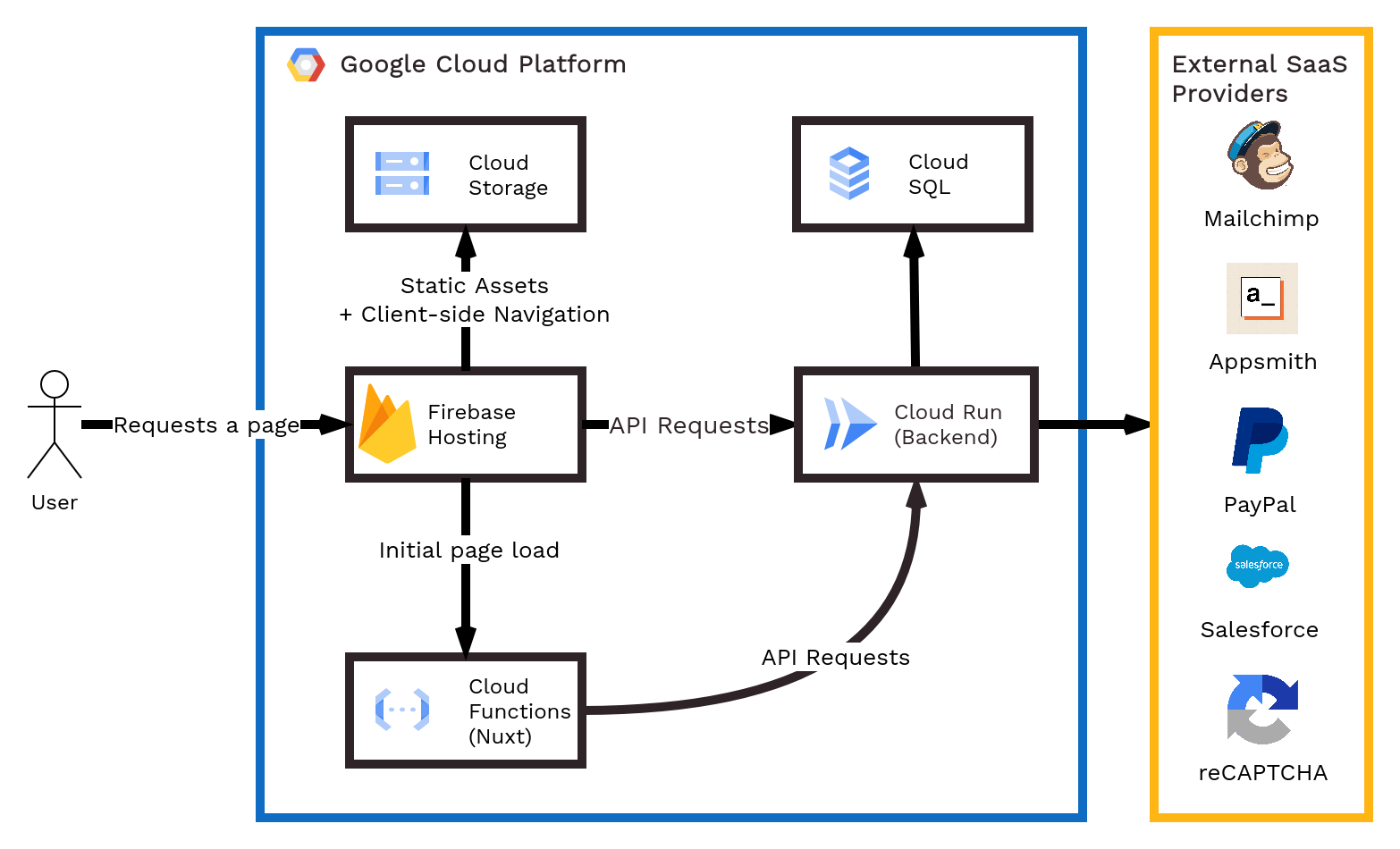
To wrap up a fairly long-winded post: we’ve cobbled together a stack based on our needs as a nonprofit serving nonprofits. The benefit of this is that it enables us to build high-quality software quickly and cheaply. The downside is that it doesn’t have a slick name like LAMP.
BaGo TyPo RuGraNux doesn’t exactly roll off the tongue,10 so we’ll just keep calling it “The Silicon Stack” for now.
One could argue that choosing a cloud provider at all is not a foregone conclusion. After all, we could run our own hardware. We could rent some space, buy some servers and network switches, wire it up, configure it, manage it, yada yada. But as it turns out, we have lots of things we want to do, and “competently manage a small data center” is not one of them. Managing our own hardware would be a truly terrible and loss-making idea even at 100x our current scale. So, we’re not doing that. ↩︎
App Engine does offer a “flexible environment” where one can run Docker containers, but it’s effectively a thin wrapper around Compute Engine (which also has its own way to run Docker containers). Specifically, App Engine Flexible doesn’t offer scale-to-zero semantics or have a free tier, both of which are important cost controls for us. ↩︎
1st gen Cloud Functions had tighter limits on request duration and concurrency, and fewer options for instance sizing, which are problematic for certain types of long-running async workloads. 2nd gen Cloud Functions is actually built on Cloud Run, but its main feature (turning your code into deployed artifacts) ends up being a limitation for us. ↩︎
Over HTTP(s) and gRPC, which ends up being important for us. ↩︎
As long as those tasks are under ~an hour apiece. ↩︎
We still use gRPC for backend service-to-service communication, where GraphQL is less of a good fit. ↩︎
Mainly due to the fact that all requests go to a single POST endpoint, and all responses (even errors!) return HTTP 200 by default. ↩︎
Type-checking even works in the HTML templates and component props! It feels like magic somtimes. ↩︎
It’s worth noting that CockroachDB is open source and can be self-hosted, which makes lock-in less of an issue. Still, there’s no reason for us to self- host our own database. ↩︎
In fact, it sounds more like a Lord of the Rings character than a software stack. ↩︎